ポケモンの強化学習AI(3)
ポケモンの最適解を知るため、強化学習を勉強している。何から始めればよいか分からなかったので、まずは強化学習で定番らしい、迷路を走破する AI を実装してみた。次に、超簡易版ポケモンをプレイする AI を実装した。 Python でなく Rust で実装したが、特に理由は無く、やってみたかっただけである。
迷路走破 AI の実装
調べてみると、強化学習においては Q 学習というものが主流らしいので、まずは Q 学習[^1]を理解&実装した。 強化学習の基本を図と数式で理解する ① - Qiitaという記事を参考にさせていただいた。図などが分かりやすく、強化学習のベースの理論がなんとなくでも分かったので、最初に読んで良かったと思う。
Rust で実装されたシンプルな Q 学習のライブラリとして、 Rurel がある。これを使っても良かったのだが、 せっかくなので Rurel のコードを読みつつ自分で実装してみた。結果的にほぼパクりになったが。
迷路はこんな感じ。

報酬は右下 (G)にたどり着いた時にだけ発生するようにした。この迷路に対して学習した結果(一部)はこんな感じになった。

単純な問題なので当たり前なのだが、普通に実装できている。
コード全体はここから確認できる。
https://github.com/acro5piano/reinforcemented-pokemon/tree/a73a94ecd62d4cfb1d1ff87c1de3b1425c6bd887
上述の Rurel と同じく、 Q 学習の部分はライブラリにして、迷路の部分は examples/ 以下のディレクトリに入れることで、汎用性を持たせることができた。ちなみに、こうした examples などの仕組みが言語レベルでサポートされているのが Rust の良いところだと思う。
簡易版初代ポケモン AI の実装
迷路が解けるようになったので、次にポケモン対戦を攻略する AI を作っていきたい。いきなり複雑なポケモンのゲームを実装しても詰まることは目に見えているので、まずは簡易版の初代ポケモンを実装する。ここでいう簡易版ポケモンとは、このようなルールである。
- 急所、外れ、ステータス変化などはなし
- ダメージは固定(乱数が無い)
- 下記 3 体から 2 体を選出
- サイドン
- じしん
- サンダース
- 10 まんボルト
- スターミー
- なみのり
- サイドン
- プレイヤーは「たたかう」か「交代」の 2 つの行動パターンを選択
各ダメージは、下記のようになっている。
| 攻撃ポケモン | サイドン | サンダース | スターミー |
|---|---|---|---|
| サイドン | 62% | 100% | 48% |
| サンダース | 0% | 16% | 74% |
| スターミー | 100% | 31% | 17% |
例えば、サイドンがスターミーに対する「じしん」は、48% (実数値 156)となる。
素早さも考慮していて、 サンダース > スターミー > サイドン の順で速い。
ちなみに Rust のコードでは、全て定数にして match で取得している。後から思うと、普通に計算する方が良かったか...
こう見ると、感覚的には、サイドンに対して何もできないサンダースが弱そうにも思えるが、一方で素早さはスターミーより速いので、うまくやれば何とかなるような気もする。
結果
学習の計測は、 ランダムにプレイする相手に対する勝率 とした。
結果は、このようになった。横軸がエピソード(一回の対戦)、縦軸が勝率である。
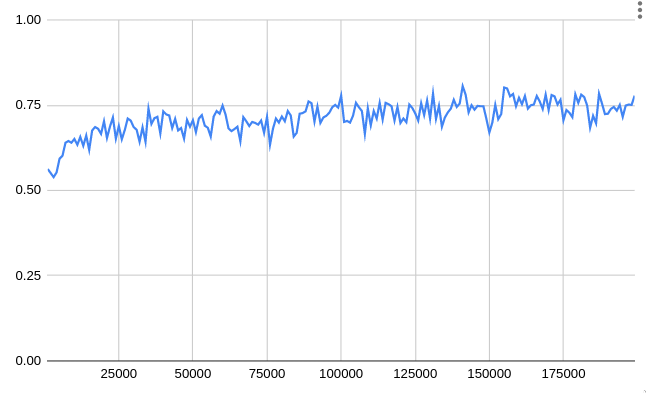
10,000 エピソードくらいで既に勝率は 7 割後半になっており、そこからは微増して 8 割程度になった。ちなみに、トレーニング済みかつ探索なしで最適行動だけを取るように設定した場合は、8 割 5 分くらいの勝率になっていた。
パラメーター (学習率, 探索率, 割引率) を色々調整してみたが、現状の実装だと 8 割が限界っぽい。
学習後の Q 値を見てみると、各ポケモンの組み合わせに対する評価は下記だった。数字が大きい方が評価が良い。
| ポケモン 1 | ポケモン 2 | 評価 |
|---|---|---|
| スターミー | サンダース | 0.338 |
| スターミー | サイドン | 0.124 |
| サイドン | サンダース | 0.109 |
| サンダース | サイドン | 0.018 |
| サンダース | スターミー | 0.096 |
| サイドン | スターミー | 0.009 |
スターミー先出し、サンダースが後発が最も良いということになった。あんま納得できないけどどうなんだろう。
確認のため、ある状態でどういう行動が評価されているか、いくつかピックアップして見てみた。
勝ち確定の状況
- AI
- サンダース (5%) (場に出ている)
- スターミー (63%)
- ランダム(敵)
- サイドン (6%) (場に出ている)
- サイドン (0%)
(敵側は同じポケモンを選出できるようになってた...)
行動の評価値は
- たたかう: 0.959
- 交代: 0.078
これは、普通に「たたかう」で勝てるので、正しい。
交代すべきシーン
- AI
- スターミー (65%) (場に出ている)
- サンダース (36%)
- ランダム(敵)
- スターミー (65%) (場に出ている)
- サイドン (0%)
行動の評価値は
- たたかう: -0.006
- 交代: 0.513
これも、交代する方が早く勝てるので、正しい。今回、勝利するまでの時間は報酬に入れていなかったが、恐らく割引価値が最大になるように調整するとこうなるのだろう。
ただ、この状況で負けるはずが無いのに、 マイナスの評価になっているのが微妙だと思った。交代しまくって負けたみたいなケースがあったのだろうか。
まとめ
素朴な Q 学習と迷路、簡易版ポケモンの実装を通じて、下記のことが理解できた。
- 強化学習の基本的なコンセプト。割引価値、報酬、環境、ベルマン方程式、e-greedy 法など。
- ポケモンのルールは、実装するとなると想像以上に複雑ということが分かった。簡易版ポケモンでも、けっこう大変だった。
- Rust に少しだけ詳しくなった。 Trait とか Generics を使ったので、良い経験になった。
次に関しては、今回の実装で、ポケモンのような複雑なゲームでは、素朴な Q 学習では対応できないような気がしている。理由は
- 状態の取りうる値が多すぎる
- 乱数や状態異常、ステータス変化、交代読み、技構成、などだけでも多すぎる。
- 初代の主要なポケモンの組み合わせだけでも、1,716 とかなりの数になる。
- これに、技構成をかけるとさらにすごい値になる。
なので、ここから先は DQN ( Deep Q Network, Q 学習と Deep Learning を合わせたもの) が必要になるのだと思われる。ちらっと本を読んだ限り、 Q を単純なテーブル(Rust 実装においては HashMap )ではなく、ニューラルネットワークで管理するようだ。
現在、下記の本を読みながら、基本的な DQN について勉強しているところなので、同じルールで Q 学習 AI と戦わせて、どうなるか見てみたい。(ブログにするより YouTube の動画にする方が面白そうだな)
機械学習スタートアップシリーズ Python で学ぶ強化学習 入門から実践まで (KS 情報科学専門書) | 久保 隆宏 |本 | 通販 | Amazon
なお、上記の本が Python ベースなのと、やはり機械学習関連は基本的に Python なので、これ以降はおとなしく Python で実装していこうと思います。 Rust もそんなに詳しくない上に、 機械学習も素人なので、一気に複数勉強するのも効率が悪い気がしている。
[^1]: Q 学習に関してはググると色々出てくるので、ここでは省略します。