ポケモンの強化学習AI(4)
ポケモンの最適解を知るため、強化学習を勉強している。今回は下記についてまとめる。
- ルールを実際のポケモン対戦に近くしたこと
- DQN を用いて、最適な行動を学習して推定する実装を書いたこと
- 結論、まだ全然ちゃんとしたものができていないこと
背景
前回の記事 では単純な 「Q 学習」によって簡易版ポケモンを攻略する AI を紹介した。が、それだとこれから本格的な AI を作っていくにあたり、限界があるのは自明である。なぜなら、 Q 学習は一度経験した状況に対しては学習結果を適用できるが、未知の状況では適用できないためだ。遷移可能な状態がほぼ決まっている簡易版ポケモンとは違い、本当のポケモンは考慮することが多く、そもそも相手がどんなポケモンを持っているかは分からないので、何らかの方法で 最適な行動を推定する 必要がある。これはポケモンに限らず、組み合わせ爆発が起こる将棋や囲碁のようなゲームでも発生する。 そこで、 Deep Q Network (以下 DQN) という手法を使うと、未知の状況でも、過去の経験から最適と思われる行動を推定することができるようなので実装してみた。
DQN は Q 学習を発展させたもので、ニューラルネットワークを使った深層学習を用いている。ニューラルネットワークというと難しそうだが、Q 学習がわかっていれば意外と概念は理解できる。 Q 学習においては、経験データは単純な「状態」と「行動価値」の組み合わせを保存する ハッシュマップ (表)だったのに対し、 DQN の場合はそれがニューラルネットワークのモデルになっている。平たく言うと回帰分析だ。ただ、ニューラルネットワークは扱いが難しいので、安定的に学習するためには様々な工夫が必要らしい。
ルール変更
DQN の必要性を感じたいため、前回使った簡易版ポケモンのルールを少し本物に近づけた。新ルールは下記。
- 引き続き、下記は考慮しない
- 「まひ」などの状態異常、追加効果
- PP
- その他、「みがわり」や「じこさいせい」などの変化わざ
- ダメージ計算は全て本物。下記を実装した。
- 乱数
- タイプ相性
- 急所
- 命中率
- 下記 3 種類から 6 体を選出(重複あり)
- サイドン
- じしん
- なみのり
- のしかかり
- いわなだれ
- サンダース
- 10 万ボルト
- にどげり
- ミサイルばり
- のしかかり
- スターミー
- なみのり
- 10 万ボルト
- サイコキネシス
- ふぶき
- サイドン
プレイヤーは「たたかう」か「交代」の 2 つの行動パターンを選択する。どのポケモンに交代するか、そしてどの技を選択するかを含めると、アクションは最大で 10 種類あることになる。今回、「6 体選出」と 「4 種の技スロット」が実装できたことが大きく、これをベースにして今後の実装を進めることもできそう。
また、このルール下では、タイプ相性と威力の観点で無駄な技も含まれている。 これらを選ぶ必要が無いということは、 AI が学習すべきである。
- サイドンは「じしん」以外の技を使う必要が無い
- スターミーは「なみのり」「10 万ボルト」以外は必要ない
- サンダースの「ミサイルばり」は必要ない
ポケモンの選出も AI でやりたいところだが、バトルとは異なる行動をどう評価するべきか分からなかったので、選出に関しては一旦ランダムでやっている。勝率の統計を取るとか、選出とバトルで学習モデルを分けるとか、色々この辺もやっていければ面白そうだと思う。
実装
本記事の時点でのコードはこれ。
https://github.com/acro5piano/pokemon_ai/tree/v0.2.0
前回までは Rust で実装していたが、 参考書 のコードが Python なのと、 Rust と機械学習を同時に勉強するのは無謀なことに気がついたので、これからは全部 Python で書いていくことにする。今回、久々にちゃんと Python を書いたが、楽しい。型ヒントが充実していて、普通に TypeScript より読みやすい気さえしてしまう。
参考書では scikit-learn の MLPRegressor 実装と Keras の両方があり、 Keras は画像を入力とする Convolutional Neural Network の実装で使われていた。今回はとりあえず MLPRegressor で進める。 Keras も使ってみたが、時間がかかりそうなのと、この程度の複雑さであれば MLPRegressor で十分解けるはずなので、一旦やめた。
説明変数 (X) となる「バトルの状態」の表現には迷ったが、 MLPRegressor では入力は 1 次元のベクトルになっている必要があるので、各要素を横に並べたベクトルにした。
- 各ポケモンの種別
- 各ポケモンの残り HP
- 各ポケモンのわざ
- 今どのポケモンがアクティブか(配列のインデックス)
- 上記を自分と相手で横に並べる
Keras というか CNN では入力を 2 次元にできるので、ここはもっと改善する必要があるかもしれない。
目的変数 (Y) となる報酬はこのように設定している。これは調整する必要がありそうで、例えば「ダメージを与えた」なども報酬に入れると良いかもしれない。
- バトルに勝利 → 1
- 敵ポケモンを 1 体倒した → 0.3
- 味方ポケモンが 1 体倒された → -0.3
- バトルに敗北 → -1
DQN の核である、行動した結果から行動状態価値を更新する部分はこんな感じになっている。ほぼ参考書の写しだが。
def update(self, experiences: list[Experience]):
states = np.array([e.state for e in experiences])
next_states = np.array([e.next_state for e in experiences])
y = self.model.predict(states)
future = self.model.predict(next_states)
for i, experience in enumerate(experiences):
reward = experience.reward
if not experience.done:
reward += GAMMA * np.max(future[i])
y[i][experience.action.value] = reward
self.model.partial_fit(states, y)価値関数の更新が最も重要なので、いきなりコードを載せてしまった。全体は下記を参照されたい。
学習過程
下記 3 種類の敵トレーナーに楽勝で勝ってくれる AI を実装したい。
StupidRandomPlayerJustAttackPlayerElitePlayer
https://github.com/acro5piano/pokemon_ai/blob/v0.2.0/pokemon_ai/simulator/sample_players.py#L17-L22
それぞれ解説する。
StupidRandomPlayer
ただランダムに交代もしくは攻撃をするプレイヤー。このプレイヤーに対しては、現状の DQN で 9 割近い勝率を出すことができた。が、これにはからくりがあり、このようなプレイヤーにはただ単に威力の高い攻撃をしていればほぼ勝ててしまう。実際 AI はそのように学習してしまっていた。なので、これには勝てて当たり前である。
JustAttackPlayer
ただランダムに攻撃をするプレイヤー。 StupidRandomPlayer とは、交代をしない点で異なる。これが意外と強く、というか AI が全然最適化できていないので、これに対する勝率が良くて 6 割くらいにしかならない。相手がランダムに攻撃をしてくるのが分かっているのであれば、有利なポケモンに交代すれば確実に勝てるはずなのだが、なぜかそういう行動を取ってくれない。
下記は一例で、 AI 側がサンダースで、 敵がサイドンの状況。サンダースはサイドンに対してほとんどダメージを与えられないので、この場合はスターミーに交代してほしいのだが、じめんに対して無効な 10 万ボルトを打ってしまっている。これでは勝てないw
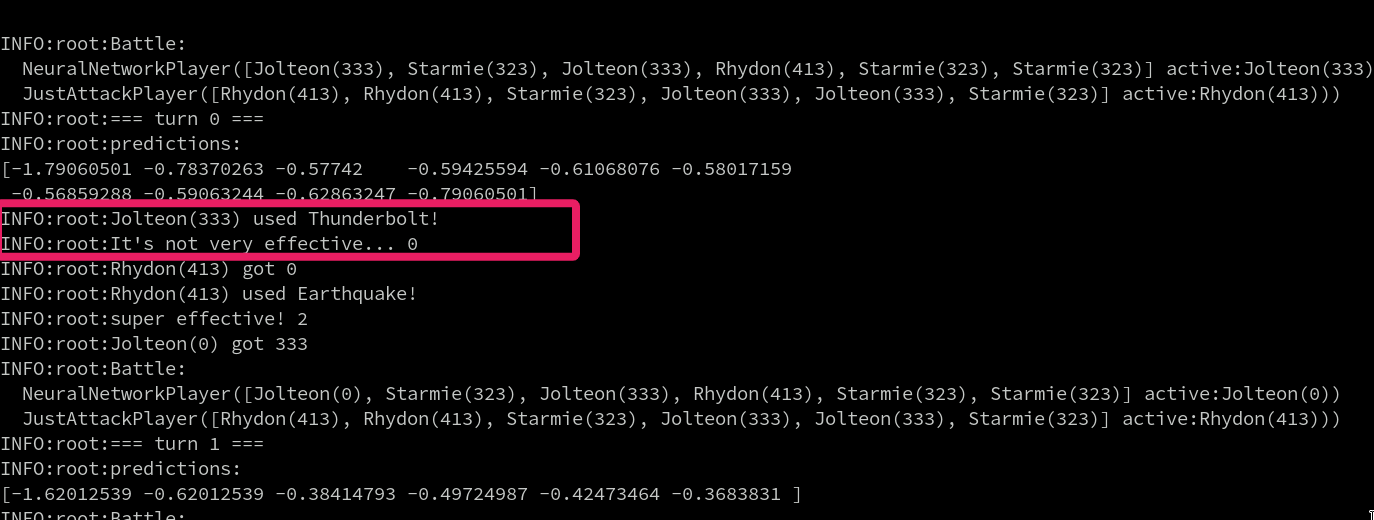
エピソード数を増やしたり、報酬を工夫するなど、色々試したが、今の所解決できていない。逆に言うと、これを解決できれば一歩成長したと言えるので、諦めずに解きたいと思っている。
ElitePlayer
いわゆるエリートトレーナー。こちらのポケモンに、常に有利になるようなポケモンに交代し、かつ効果が抜群の技を使用してくる。 JustAttackPlayer にすら勝てていないので、 ElitePlayer に勝てたら大きな進歩と言えるだろう。
総括
DQN 実装したが、全然ちゃんとした学習ができていないので、モデルが悪いのか、アルゴリズムが悪いのか、何かしらバグを作ってしまっているのか、引き続き検証していきたい。