ポケモンの強化学習AI(5)
ポケモンの最適解を知るため、強化学習を勉強している。
現在は、下記のルールで定義される簡易版初代ポケモンにおいて、 JustAttackPlayer というただランダムに攻撃してくるプレイヤーに勝利することが目標。
- ダメージ計算は本物のルールと同じ
- 「まひ」などの状態異常、追加効果、PP、「みがわり」や「じこさいせい」などの変化技は考慮しない
- 下記 3 種類から 6 体を選出(重複あり)
- サイドン
- じしん
- なみのり
- のしかかり
- いわなだれ
- サンダース
- 10 万ボルト
- にどげり
- ミサイルばり
- のしかかり
- スターミー
- なみのり
- 10 万ボルト
- サイコキネシス
- ふぶき
- サイドン
相手がただランダムに攻撃を繰り出してくるだけであれば、AI 側は有利なポケモンに交代して急所を突けば 100%近い勝率で勝てるはずのだが、実装中の AI はそういう行動を取ってくれない。試したことを本記事にまとめていく。
エピソード数を極端に増やす
ここでいう「エピソード」とは、一回の対戦のことだ。普段は 10,000 エピソードでやっていて、試しに 1,000,000 エピソードにしてみたが、結果はほとんど変わらなかった。
6 体ではなく 1 体選出にして実験
ポケモンの交換にハードルがありそうなので、一旦 1:1 でどうなるか見てみた。
1. 同じキャラで対戦
スターミー vs スターミー
- 予想: AI は 「10 万ボルト」だけを選ぶようになる
- 結果: 予想通り
初回の各アクションの評価値はこのようになっていた。追加効果が無いルール下なのに、「なみのり」が「サイコキネシス」「ふぶき」より低いのは気になったが、まあ良いだろう。
| わざ | 評価値 |
|---|---|
| なみのり | 1.08013507 |
| ふぶき | 1.01979777 |
| サイコキネシス | 1.02257167 |
| 10 万ボルト | 1.12629682 |
ちなみに、バトルのログを出力できるようにしており、 --debug を引数で与えるとこういうログが出力される。
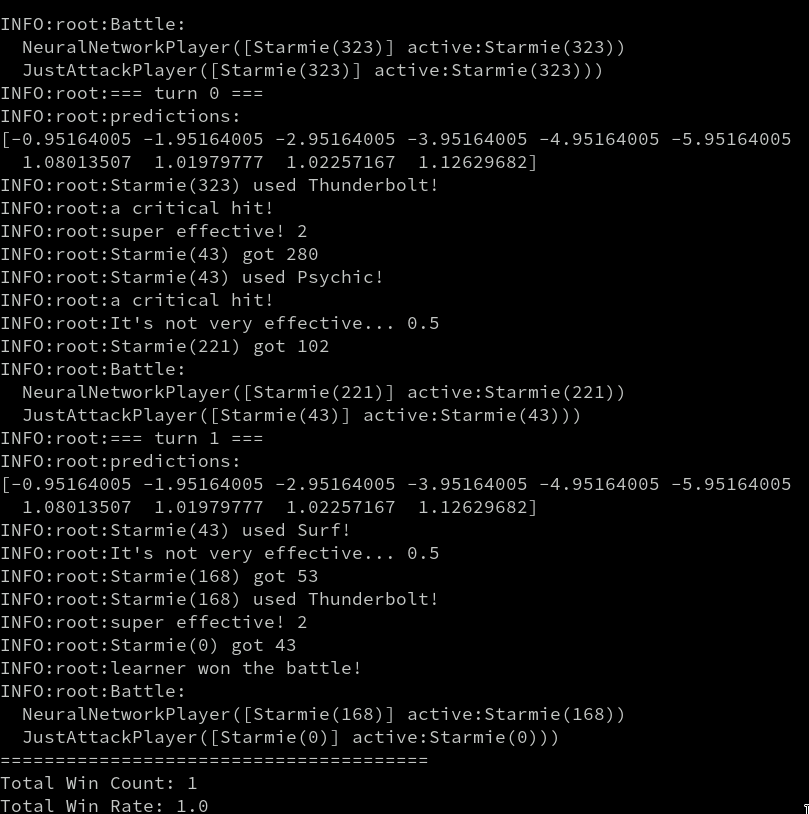
サンダース vs サンダース
- 予想: AI は 「のしかかり」だけを選ぶようになる(電気は半減だから、10 万ボルトは選ばれない)
- 結果: 予想通り
初回の各アクションの評価値はこのようになっていた。
| わざ | 評価値 |
|---|---|
| 10 万ボルト | 0.59328783 |
| のしかかり | 0.62921857 |
| にどげり | 0.4926584 |
| ミサイルばり | 0.4386187 |
ただし、正しく学習できていない場合があった。全く同じコードで学習しているにもかかわらず、学習が安定しないというのは、参考書に事例としてあったが、手元でも再現できるとは...
対策として、単純にエピソード数を増やせば、この状態にならなくなった。通常は 10,000 エピソードでやっているが、それを 100,000 に増やすと、この現象はなくなった。
サイドン vs サイドン
- 予想: AI は 「なみのり」もしくは「じしん」だけを選ぶようになる(どちらでも勝率は同じ)
- 結果: 予想通り
初回の各アクションの評価値はこのようになっていた。「なみのり」の方が大きいダメージを与えられることをなぜか認識しているのが面白かった。急所を考えても、どちらも 2 発で倒せるので、変わらないかと思ったが。「いわなだれ」とかの行動も学習の初期では実行されるから、それらのセットで計算されたのだろう。
| わざ | 評価値 |
|---|---|
| じしん | 0.77746616 |
| いわなだれ | 0.44575743 |
| なみのり | 0.81661485 |
| のしかかり | 0.54310359 |
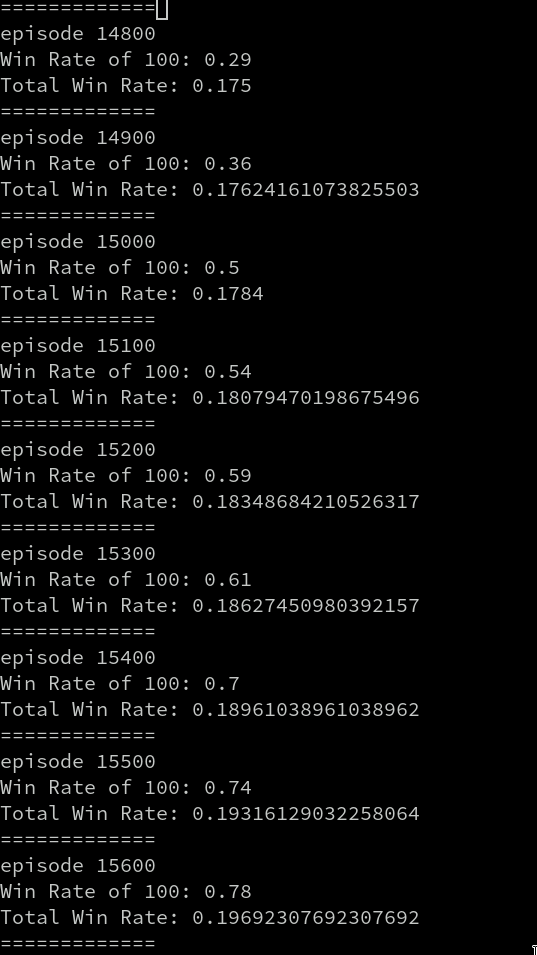
面白かったのが、安定して勝てるようになるまでは、スターミーの時と比べてより多くのエピソード数が必要だったことだ。この画像のように、エピソードが 15,000 を超えたくらいから、やっと勝てるようになる。この傾向は何回試しても同じだった。
先述のサンダースの件とも共通点しているのは「勝てる行動がはっきりと分からなそう」ということだ。例えば、
- サイドンであれば、「なみのり」「じしん」どっちでも勝てる
- サンダースが「のしかかり」と「10 万ボルト」与えるダメージは近い
- 敵もランダムとはいえ相応のダメージを与えてくる
このことから推測できるのは、「成功体験を積むのが早い方が、学習が進む」ということか?人間でもそれは本当にそうだが。
2. AI にとって不利なキャラ選出
最悪の相性といってよい、
- AI: サンダース
- 敵: サイドン
の組み合わせを試してみた。 AI が勝つためには、「にどげり」を急所に当ててダメージを稼ぎつつ、敵が「じしん」を選ばない可能性に賭け続けるしかない。
- エピソード数: 100,000
- 予想: AI は 「にどげり」だけを選ぶようになる
- 結果: ほぼランダムに近い行動しか取らない!
初回の各アクションの評価値はこのようになっていた。
| わざ | 評価値 (*1000) |
|---|---|
| 10 万ボルト | 0.171788381 |
| のしかかり | 9.19548280 |
| にどげり | -4.83512550 |
| ミサイルばり | 3.59839882 |
なぜか「にどげり」の評価値が低い。これでは勝てないw
次に、相手のサイドンが「じしん」以外を選んだ場合はこうなっていた。(「じしん」の場合、確定 1 発なのでゲームが終わってしまう)
- AI: サンダース (残 85%)
- 敵: サイドン (残 94%)
| わざ | 評価値 |
|---|---|
| 10 万ボルト | -0.01571551 |
| のしかかり | 0.05194992 |
| にどげり | -0.04728442 |
| ミサイルばり | 0.03635794 |
ここでも、「にどげり」の評価が低すぎる。原因は、100,000 回のエピソードで、勝ったのはわずか 154回という、「成功体験の少なさ」だと思われる。確かに、現在の報酬は「勝利」だけなので、データが少なくほとんど学習が進まないことになってしまうのだろう。
敵が最初からそこそこ強い行動を取ってくる場合、成功体験が無いため学習が進まない。
小さな成功体験を積むため、 敵に与えたダメージを報酬に入れた方が良さそう だ。さっそく与ダメージを報酬に入れる実装を開始しても良いのだが、その前に強化学習でたまに出てくる「カリキュラム学習」を取り入れる実験をしてみたい。「カリキュラム学習」とは、最初は簡単なタスクをこなし、徐々に複雑なタスクを実行できるようにする、というものだ。
カリキュラム学習
AI「サンダース」が、敵の「サイドン」に少しでも勝つために、学習を 2 段階に分ける。
- ある回数までは、敵サイドンが「なみのり」しかやらない状態でトレーニング
- 次に、敵サイドン任意の行動を取れる状態でトレーニング
これで、 各アクションに対して正しい評価値を出力できていれば、カリキュラム学習の成果があると言える。
実装
カリキュラム学習の境界は、ここでは 50,000 対戦とした。サイドンが「なみのり」しかできないとはいえ、サンダースはサイドンにほとんどダメージを与えられず勝率が低いはずなので、それなりの試行回数が必要だと思ったためだ。
実装的にはこんな感じ。
if episodes < 50000:
self.opponent = JustAttackPlayer(
[
p.Rhydon([m.Surf(), m.Surf(), m.Surf(), m.Surf()])
]
)
else:
self.opponent = JustAttackPlayer(
[
p.Rhydon([m.Earthquake(), m.RockSlide(), m.Surf(), m.BodySlam()]),
]
)結果
50,000 エピソードまで
当然といえば当然だが、各技に対する評価値は正しくなっていた。
| わざ | 評価値 |
|---|---|
| 10 万ボルト | 0.65001931 |
| のしかかり | 0.69079102 |
| にどげり | 0.86724983 |
| ミサイルばり | 0.56955266 |
100,000 エピソード
ところが、100,000 を実行すると、「ミサイルばり」を評価するようになってしまった。特に序盤。
| わざ | 評価値 |
|---|---|
| 10 万ボルト | -0.02667049 |
| のしかかり | -0.09929604 |
| にどげり | -0.0216659 |
| ミサイルばり | -0.01326972 |
恐らくだが、 50,000 を超えた分に関しては、「にどげり」を使っても負けることが多いため、評価値が低くなってしまうのだろう。
カリキュラム学習(改)
ランダムだと評価値が逆転してしまうのを回避するため、エピソード数を増やすにつれて、「弱サイドン」の出現数を確率的に減らすようにしてみた。
if episodes / max_episodes < random(): # <------------ ここ
self.opponent = JustAttackPlayer(
[
p.Rhydon([m.Surf(), m.Surf(), m.Surf(), m.Surf()])
]
)
else:
self.opponent = JustAttackPlayer(
[
p.Rhydon([m.Earthquake(), m.RockSlide(), m.Surf(), m.BodySlam()]),
]
)結果はこうなった。
| わざ | 評価値 |
|---|---|
| 10 万ボルト | 0.35495972 |
| のしかかり | 0.61806889 |
| にどげり | 0.47822885 |
| ミサイルばり | 0.32660102 |
今度は「のしかかり」の評価が高くなってしまった。学習の様子としては、15,000 回くらいで勝率 6-7 割をマークし、そこから下がる、という想定通りの動き。何回試しても、「にどげり」を選択するようにはなってくれなかった。
うーん、うまくいかない。
「過学習」と思われるので、色々調べた結果、データが不足している場合に過学習になりにくいとのことだったので、エピソード数を 200,000 に増やしてみた。その結果、 初手「にどげり」を選択するように 、改善された。
| わざ | 評価値 |
|---|---|
| 10 万ボルト | 0.46917974 |
| のしかかり | 0.26899481 |
| にどげり | 0.58559038 |
| ミサイルばり | 0.51377925 |
ただし、ゲームの後半(4 ターン以降)になると、なぜか「ミサイルばり」を打つようになってしまった。
| わざ | 評価値(4 ターン目) |
|---|---|
| 10 万ボルト | 0.3876465 |
| のしかかり | 0.14505879 |
| にどげり | 0.45607543 |
| ミサイルばり | 0.51325985 |
そのまま「にどげり」やってれば勝てるのに、歯がゆい。ちなみに、性能評価は「なみのり」しか打たない「弱サイドン」の方で実験している(通常サイドンだと、「じしん」でゲームが終わってしまうので、効率が悪い)。
これは、ゲーム後半になると、「にどげり」を打って負けるシーンが多かったため、このように学習してしまったのだろう。そこで、エピソード数を更に増やして 500,000 エピソードで実験した結果、全てのターンで「にどげり」を出すようになった!
| わざ | 評価値 |
|---|---|
| 10 万ボルト | 0.6476353 |
| のしかかり | 0.47632443 |
| にどげり | 0.80536741 |
| ミサイルばり | -0.27786236 |
効果が無いはずの「10 万ボルト」の評価がやや高いのが気になるが、学習の回数を増やせば、常に「にどげり」を出してくれることが分かったので、一旦カリキュラム学習に関してはこれで良しとする。
ここまでで、分かったことは
- 強化学習において、極端に勝ちやすかったり、勝ちにくかったりすると、学習が全然進まない
- カリキュラム学習で、最初は「手加減」し、徐々に難しくしていくことで、学習がはかどる
- ただし、カリキュラム学習は(カリキュラム学習しなくて良いケースと比較して)通常より多いエピソード数が必要
こうしてみると、人間とそっくりで面白い。確かに、問題が簡単すぎると、「解ければいいや」となり、それ以上学習しないしな。
次の予定
カリキュラム学習で時間を使ってしまったので、「与えたダメージを報酬に入れる」というのは次回に回す。